
2.2 匹配
可以被描述成如下流程:S1:用户通过聊天界面向系统提出一个话题;S2:系统对该话题进行分词处理;S3:在系统知识库中寻找与该话题匹配的话语回复用户。
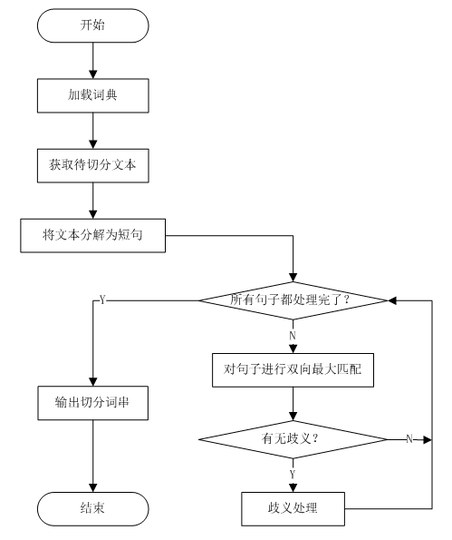
基于词典的分词算法分为词典加载、预处理、最大匹配、歧义消解几个阶段。
其具体流程如下:
S1:预处理阶段,按照特殊字符(英文字母、数字、标点符号等)将待分析文本进行断句,将待切分的文本切分为只有中文的短句子,这些句子是下一步分词处理的基本单位;
(举个栗子:输入“asdfadf东北师范大学哈哈哈dfadflakfl(*^__^*) 嘻嘻……”,simi只会对其中的中文“东北师范大学哈哈哈嘻嘻”做出响应;输入“(*^__^*)”时,输出“I have no response.”)
S2:对断句出来的句子进行双向最大匹配(双向匹配,长词优先)分词,分词后的结果作为S3的输入;
(举个栗子:输入“东京古巴比伦”,正向与反向切词结果均为《东京,古巴比伦》,长词优先,所以simi只对“古巴比伦”做出响应;输入“古巴比伦埃菲尔铁塔”,正向与反向切词结果均为《古巴比伦,埃菲尔铁塔》,此时Simi对“埃菲尔铁塔”做出响应)
S3:对上一步分词得到的结果进行比较,判断是否存在歧义,如果存在歧义,就进行一定的歧义消解;
S4:重复S2、S3,直到处理完步骤一中断句所切分出的所有句子单元。
算法流程如图所示:
这里给出与小黄鸡对话的例子:我问小黄鸡:“埃菲尔铁塔上45度角仰望星空”。
S1:双向最大匹配分词:正向反向均为《埃菲尔铁塔上,45度角,仰望星空》,没有歧义。长词优先,系统选择了“埃菲尔铁塔上”作为关键词;
S2:系统在知识库中用刚才说的哈希函数f(埃菲尔铁塔上),找到比如[埃,11,P] 的表项,顺着指针找到6字词的索引,顺着索引找到6字词表,遍历词表,找到<埃菲尔铁塔上,…>结构体;
S3:系统随机选择该结构体Ans域中的一个回答(也有可能是根据频率高低来选择)。比如“两年之后等着你”。
S4:输出回答,匹配结束。
Part 3 如何自制小黄鸡
根据第二部分所介绍的原理,个人想要真正完成整个小黄鸡的制作是有难度的。如果能做出一个智能较高的聊天机器人,那直接可以去申请专利开公司了~
所以在这里我们介绍两种比较简单易行的方法,跳过对智能算法的研究,直接调用SimSimi的库。
3.1 通过获取Cookies方法
首先我们来看人人网小黄鸡是怎么做的。
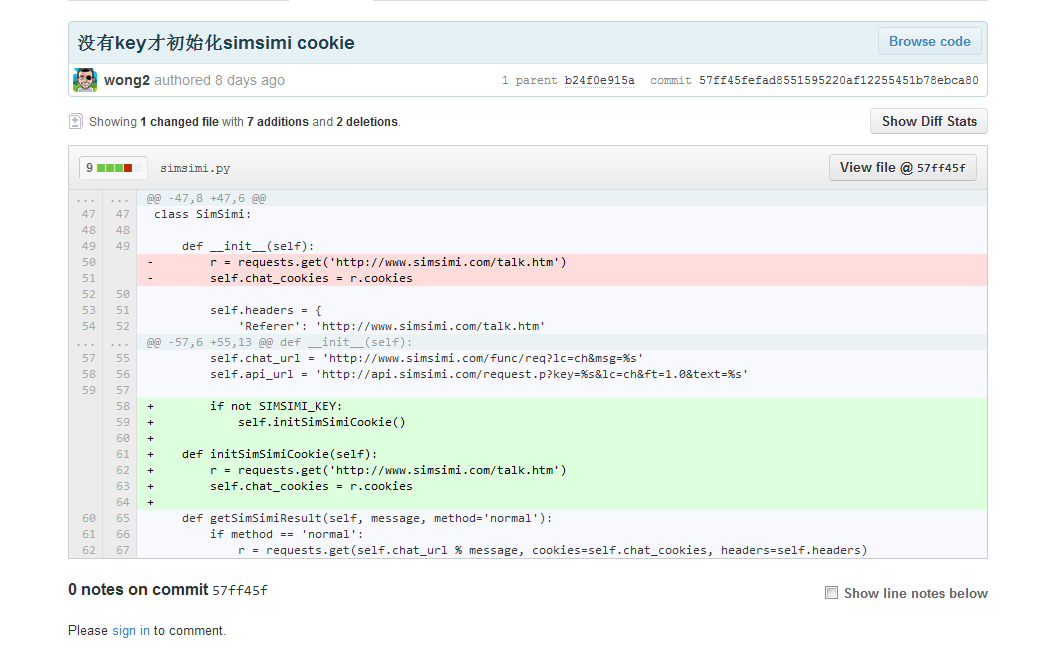
原作者团队在github上给出了源代码,网址https://github.com/wong2/xiaohuangji,他们使用Python语言,获取Cookies,通过人人网的接口,将Simi的库连接到人人上。
也就是说,人人网小黄鸡并没有真正研究第二部分讲到的 AI聊天机器人的算法,而是通过调用人家Simi的库!这就是人人网小黄鸡跟Simi的关系。
Cookies:指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。利用网页代码中的HTTP头信息进行传递。
(举个栗子,我们第一次登录保研论坛时输入用户名与密码,然后选择保存密码,就相当于保存Cookies,下次再打开eeban就不用再登录了~
Cookies作为一个大有用处的存在,同时也极大地危害着网络信息安全。因为是可以通过例如JS脚本等方法窃取Cookies的。想想看,别人获取了你的Cookies,都不用知道你的用户名密码就能以你的身份查看邮件,浏览网页等等……当然这是题外话,有兴趣的我们以后讨论~所以希望大家能经常清理自己的Cookies,不给坏人可乘之机~~)
回到我们的小黄鸡,下图是人人网小黄鸡源代码中关于获取Cookies的一段:
我们要自制呢,就不用他们那么麻烦~咱们只要几行小代码就可以了~
简单介绍一下核心算法:
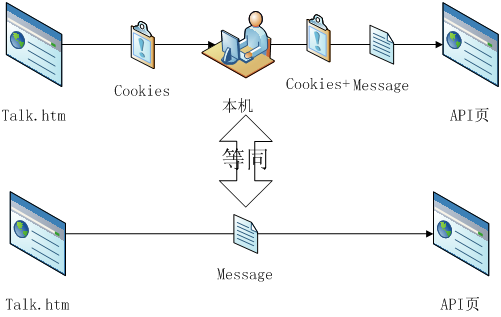
S1:利用session对象获取本机在http://www.simsimi.com/talk.htm 上的Cookies
(session,在网络应用中被称为“会话”。简单地说,它就像在网站顶层的一个盒子,无论网页怎么跳转,都能够保存用户的信息。这里注意!Talk页是Simi免费的聊天页面,这一点很重要!)
S2:构造头信息,准备将Cookies添加在HTTP头部信息中
S3:从SimSimi API接口中获取本机的响应
(刚才说过,Cookies利用HTTP头信息进行传递,所以我们将刚才talk页上的Cookies添加在 API页上,相当于是talk页在调用API!!!这一点很重要。
举个栗子,我们拿着一把锁,去找talk页,talk给了我们一把钥匙,但是我们开锁手法我们不知道,于是我们将锁+钥匙一起送给API,然后它帮我们打开了盒子~~~bling~~bling~~)
来,我们看看原理图:
下面是我用这个方法做的小黄鸡1号:
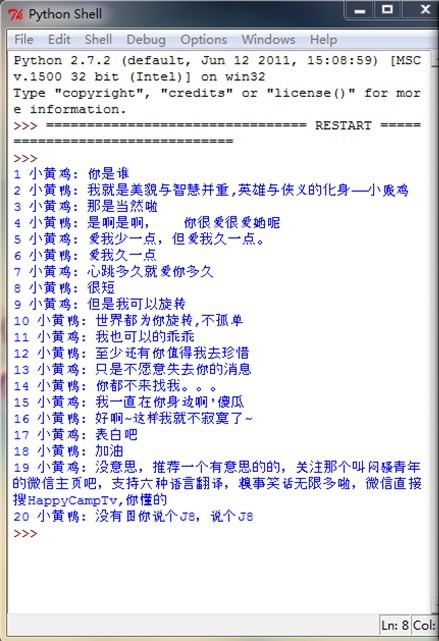
确切的说是这是一只小黄鸡与一只小黄鸭的互掐。哈哈!
想要做小黄鸡,这是一个省时省力的方法,但是。。。不得不说这是在盗用SimSimi的劳动成果。。。人家指望它的API库卖钱的呢。。。。额额额
所以接下来我们来看正版的制作方法~~
3.2 通过key调用API接口
下面这个网址给出了SimSimi的官方API文档:http://developer.simsimi.com/api
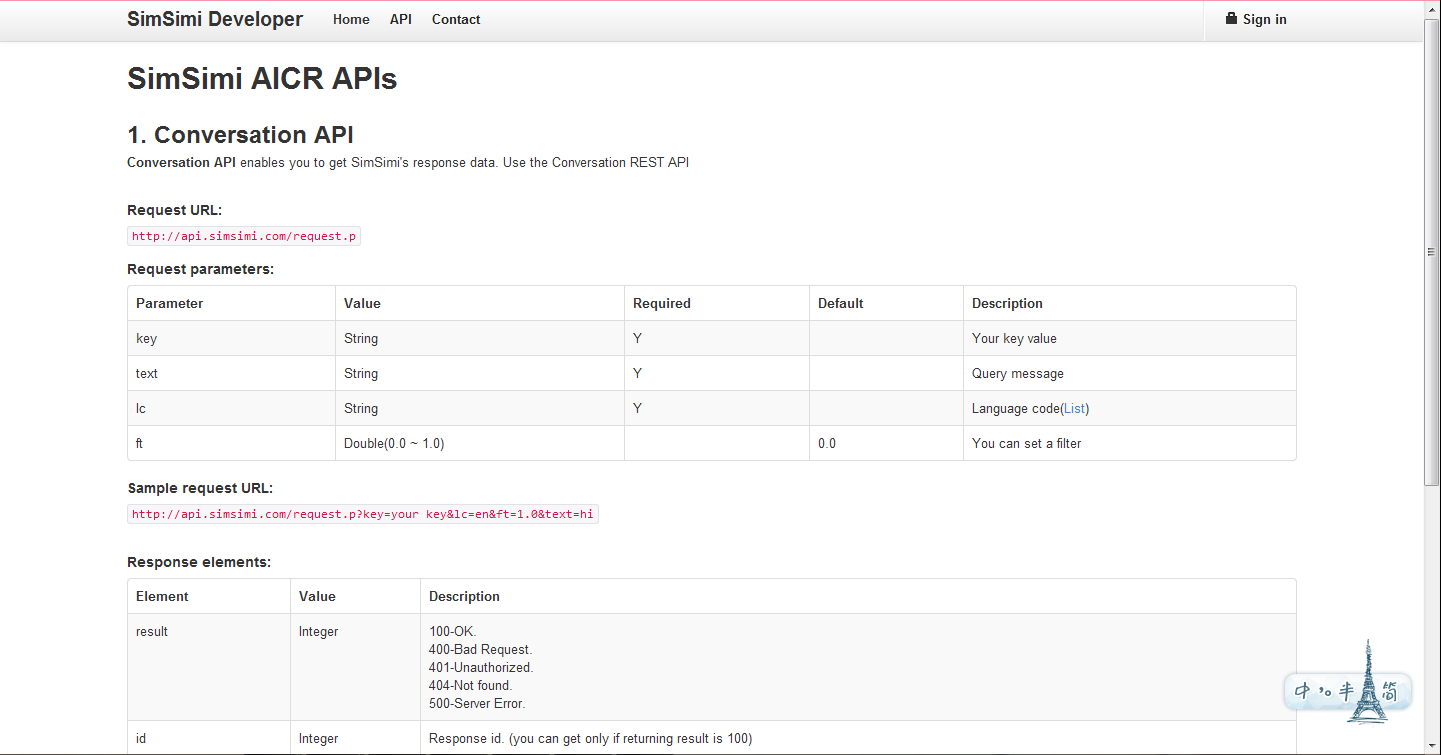
文档已经写得非常清晰了,http://api.simsimi.com/request.p?key=your key&lc=en&ft=1.0&text=hi这一行代码就是在调用官方API接口!也就是说,只要你申请到了key,就能调用simi的API,是不是想想就很爽?~最开始我给大家的小黄鸡2号就是正版鸡有木有~现在来讲解一下怎么做。我选择J2EE平台,MVC模式,JSP+JAVA语言。
最核心的思想是这样的:我们将从表单中获取的字符串,送去调用官方API接口,用request对象返回结果,再打到屏幕上~~是不是很简单?
下面介绍详细算法流程:
S1:talk.jsp——用户填写表单内容,将参数String text传递给chuil.jsp;
S2:chuli.jsp——request对象获取传递来的参数,调用API,用Content类中的getContent(urls)方法获取网页的内容,返回结果String ans,将ans传递给talk.jsp;
S3:talk.jsp——request对象获取传递来的参数ans,将ans打印到屏幕上。结束。
*其中Content类用于获取网页内容,直接上网找的,都不用自己写~hiahia
这是小黄鸡2号的效果图:
正版的方法就是简单~但是因为是正版的,就得付出代价,key是要钱的。我现在用的是试用版,key的有效期限是90天,并且每天只有100次响应,也就是说你一天只能调戏它100次。。。是不是很桑感。
总结
经过这么多的介绍,大家是不是对类似小黄鸡(SimSimi)的人工智能聊天机器人有了初步的认识。其实你可以做很多只“小黄鸡”,但它的核心都是Simsimi的库,是人家的东西。所以说偶们新时代的年轻人应该要有自己创新意识~让我们来开发自己的智能算法~做自己的小黄鸡、小黄鸭、小黄狗、小黄瓜吧!~~
问答环节
训练的话玩家调戏它的数据会被录入作为以后回答别人的参考么?还是需要相应权限才能存入库里?
这个就是教学界面。会的。玩家教给它的话题,会在切词之后,打包它的回答,一起存入词库。别人触发相似的关键词,也有可能回答刚刚你教过的答案。
那一个问题有不同答案,如何选择呢?
一个关键词下链接了好几种不同的回答,系统会随机选择一个,比如输入“哈哈”,回答有可能是“呵呵”“笑什么笑”……
以前的这个词表里面对于每个可能出现的词已经有了确定的答案的意思吗?
对,构建词库的时候,还有训练的时候都已经写进去了
但是训练的时候不能随便的吧?万一教他的是错误的知识呢?
谁都可以~~但是一般会有过滤系统,要审核的,像simi就有做任务这个玩法,任务就是,给你别人的回答,让你判断是否可以给不满16岁的孩子看,也有存进去的时候设置敏感词什么的。