

CommonsenseQA是为了研究基于常识知识的问答而提出的数据集,比此前的SWAG、SQuAD数据集难度更高。目前最流行的语言模型BERT在SWAG、SQuAD上的性能已经接近或超过人类,但在CommonsenseQA上的准确率还远低于人类。

CommonsenseQA数据集上的常识问题,大拇指朝上的选项为正确答案
自然语言理解(NLP,Natural Language Processing)是人工智能皇冠上的明珠,常识推理则是难度最高的NLP任务之一。在机器翻译、阅读理解等NLP任务上,AI的表现已经接近或超过人类水平,阿里AI就先后在国际顶级的机器翻译赛事WMT、机器阅读理解赛事SQuAD、文本阅读理解挑战赛MS MARCO等赛事夺冠甚至赶超人类纪录。
相比之下,AI的常识推理能力比人类差得多。常识是指绝大部分人都了解并接受的客观事实,比如盐是咸的、下雨了要打伞、村庄位于陆地上而非湖泊内等等。人在回答问题时,常会结合这些不言而喻的背景知识。但机器没有常识,无法将“马路上,人们撑着伞”的原始陈述与“外面正在下雨”的逻辑假设自动关联。
深度学习领军人物之一、图灵奖获得者Yann LeCun 曾有断言:最聪明的AI在常识方面也不如猫。在包含1.2万多个常识问题的CommonsenseQA数据集上,最流行的AI模型BERT的答题准确率为56.7%,远低于人类的89%。
阿里巴巴达摩院语音实验室提出了AMS方法,显著提升BERT模型的常识推理能力。AMS方法使用与BERT相同的模型,仅预训练BERT,在不提升模型计算量的情况下,将 CommonsenseQA数据集上的准确率提升了5.5%,达到62.2%。
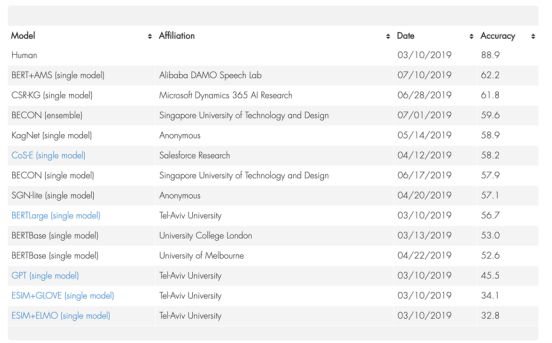
CommonsenseQA数据集的得分榜单,阿里AI刷新了世界纪录
阿里的技术突破将大幅提升下一代人机交互产品的常识理解能力,可应用于语音导航、智能电视、语音售票机等产品。
设想这样的场景:你开车寻找一个地处偏僻的村庄,村子不久前已经搬迁,但导航还没更新位置信息。村子所在地块被开挖成了人工湖,由于AI没有常识,导航直接就把你往湖心方向带。AI如果拥有常识,就不会犯这类“蠢萌”的错误。
达摩院表示今后将开源该模型和论文,与业界共享最新成果。