

11月12日,阿里云通义大模型团队开源通义千问代码模型全系列,共6款Qwen2.5-Coder模型。相关评测显示,6款代码模型在同等尺寸下均取得了业界最佳效果,其中32B尺寸的旗舰代码模型在十余项基准评测中均取得开源最佳成绩,成为全球最强开源代码模型,同时,该代码模型还在代码生成等多项关键能力上超越闭源模型GPT-4o。基于Qwen2.5-Coder,AI编程性能和效率均实现大幅提升,编程“小白”也可轻松生成网站、数据图表、简历、游戏等各类应用。
编程语言是高度逻辑化和结构化的,代码模型要求理解、生成和处理这些复杂的逻辑关系和结构,通常也被认为是大模型逻辑能力的基础来源之一,对于整体提升大模型推理能力至关重要。Qwen2.5-Coder基于Qwen2.5基础大模型进行初始化,使用源代码、文本代码混合数据、合成数据等5.5T tokens的数据持续训练,实现了代码生成、代码推理、代码修复等核心任务性能的显著提升。
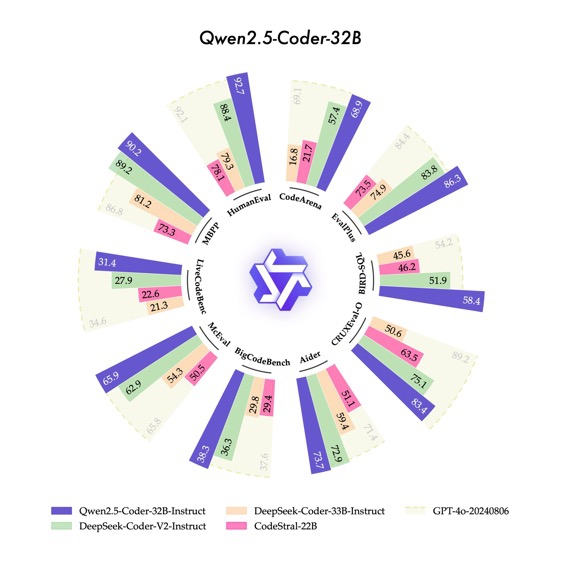
其中,本次新发布的旗舰模型Qwen2.5-Coder-32B-Instruct,在EvalPlus、LiveCodeBench、BigCodeBench等十余个主流的代码生成基准上,均刷新了开源模型的得分纪录,并在考察代码修复能力的Aider、多编程语言能力的McEval等9个基准上优于GPT-4o,实现了开源模型对闭源模型的反超。
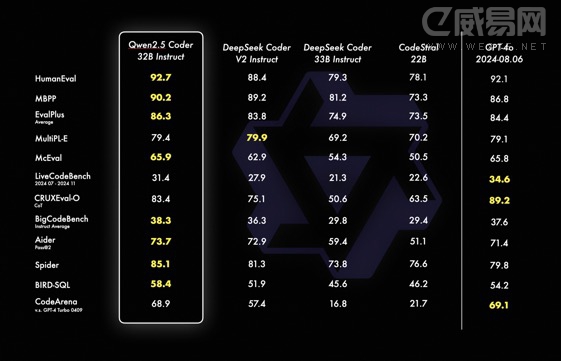
在代码推理方面,Qwen2.5-Coder-32B-Instruct刷新了CRUXEval-O基准开源模型的最佳纪录。Qwen2.5-Coder-32B-Instruct在40 余种编程语言中表现优异,在McEval基准上取得了所有开闭源模型的最高分,并斩获考察多编程语言代码修复能力的MdEval基准的开源冠军。
此次开源,Qwen2.5-Coder推出0.5B/1.5B/3B/7B/14B/32B 等6个尺寸的全系列模型,每个尺寸都开源了Base 和 Instruct 模型,其中,Base模型可供开发者微调,Instruct模型则是开箱即用的官方对齐模型,所有Qwen2.5-Coder模型在同等尺寸下均取得了模型效果最佳(SOTA)表现。

Qwen2.5-Coder全系列开源,可适配更多应用场景,无论在端侧还是云上,都可以让AI大模型更好地协助开发者完成编程开发,即便是编程“小白”,也可基于内置Qwen2.5-Coder的代码助手和可视化工具,用自然语言对话生成网站、数据图表、简历和游戏等各类应用。
截至目前,Qwen2.5已开源100多个大语言模型、多模态模型、数学模型和代码模型,几乎所有模型都实现了同等尺寸下的最佳性能。据了解,全球基于Qwen系列二次开发的衍生模型数量9月底突破7.43万,超越Llama系列衍生模型的7.28万,通义千问已成为全球最大的生成式语言模型族群。