

FineReader Engine12是ABBYY全面利用人工智能与机器学习的一大力作。有赖于人工智能与机器学习算法,新版本对识别过程进行了优化和调整,提供文档分类、文档中对象与图表识别、多种语言识别以及布局重建等强大功能,可帮助软件公司、系统集成商和其它企业客户开发更高质量的文档处理解决方案。
“ABBYY FineReader Engine 12满足了在虚拟机或云端使用OCR和数据捕获的应用程序不断增长的需求。该SDK使企业和组织能够自由地开发最适合其业务目标的软件,其先进的功能和可识别200余种语言的强大能力,将有力地帮助各类客户进军新市场,”ABBYY负责SDK的全球产品营销高级总监雷纳·保赫(Rainer Pausch)博士评论说。
OCR识别能力再升级 两大亮点树立行业新标杆
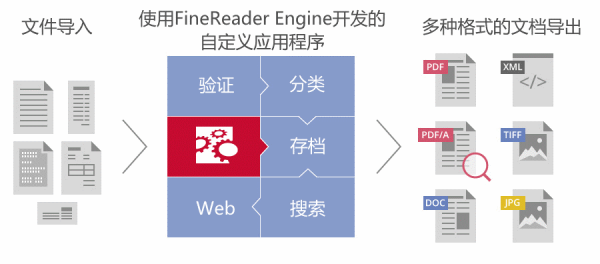
一直以来,ABBYY以其世界领先的OCR技术引领行业的质量和可靠性标准。通过FineReader Engine 12 开发的应用程序可具备文本识别、PDF转换和数据捕获功能,可将扫描文档转换为可搜索的PDF、PDF/A、Word或Excel文档,并可访问照片、屏幕截图、工业显示器或汽车仪表板和信息娱乐系统上的数据。使用该工具包,应用程序能够将TIFF库转换为PDF、PDF/A、Word或其他格式,并准确提取字段值。
同时,新版本的SDK更拥有布局重建功能和多语言文本处理能力两大亮点。
FineReader Engine 12的强化布局重建依赖于ABBYY自适应文档识别技术与机器学习算法,增加了识别和还原文本平衡栏的功能,还对识别表格及其布局重建功能进行升级。企业不仅可以创建可搜索与可编辑的文档,而且这些文档与扫描或拍摄的原件完全匹配。这一功能对于企业有效处理大量财务文档极其重要。
依托强大的人工智能技术,FineReader Engine 12可支持208种语言。该新版本SDK对日语的光学字符识别(OCR)技术进行了改进,并加入波斯语作为一种新的识别语言, 使ABBYY继续保持在可识别语言总数上的领先。更加值得注意的是,此次升级强化了对同一文档中出现的多种语言进行处理的能力,大大加强了多语言文档的识别准确度,并可生成保留原始布局的可搜索和可编辑的数字副本。
高可用性和多配套平台 助力企业抢占市场
目前,适用于Windows、Linux、Mac系统以及嵌入式系统的FineReader Engine 12 版本已经在全球上市。 该SDK同时可以集成到在“阿里云”和微软云(Microsoft Azure)等云平台上运行的应用程序中,并支持虚拟环境,拓宽了提供软件应用和服务的范围。
同时,FineReader Engine 12还提供了轻松集成、预配置工具、代码示例等其他组件,可大大缩短OCR应用产品的开发时间,有助于软件公司、系统集成商和企业在当今快速发展的商业环境中超越竞争对手,占得市场先机。