每次新模型发布,通稿里少不了"史上最强""全面超越"。看多了就麻木了。到底强了多少?值不值得多付那几倍的钱?
aiiq.org给了一个回答——给每个模型一个 IQ 分数和一个 EQ 分数,放在同一张图上比。IQ 来自 12 个公开基准测试,EQ 来自人类投票和 AI 评分。再加上成本维度,就是"能力、情商、花钱"三个轴的取舍。

先看排名
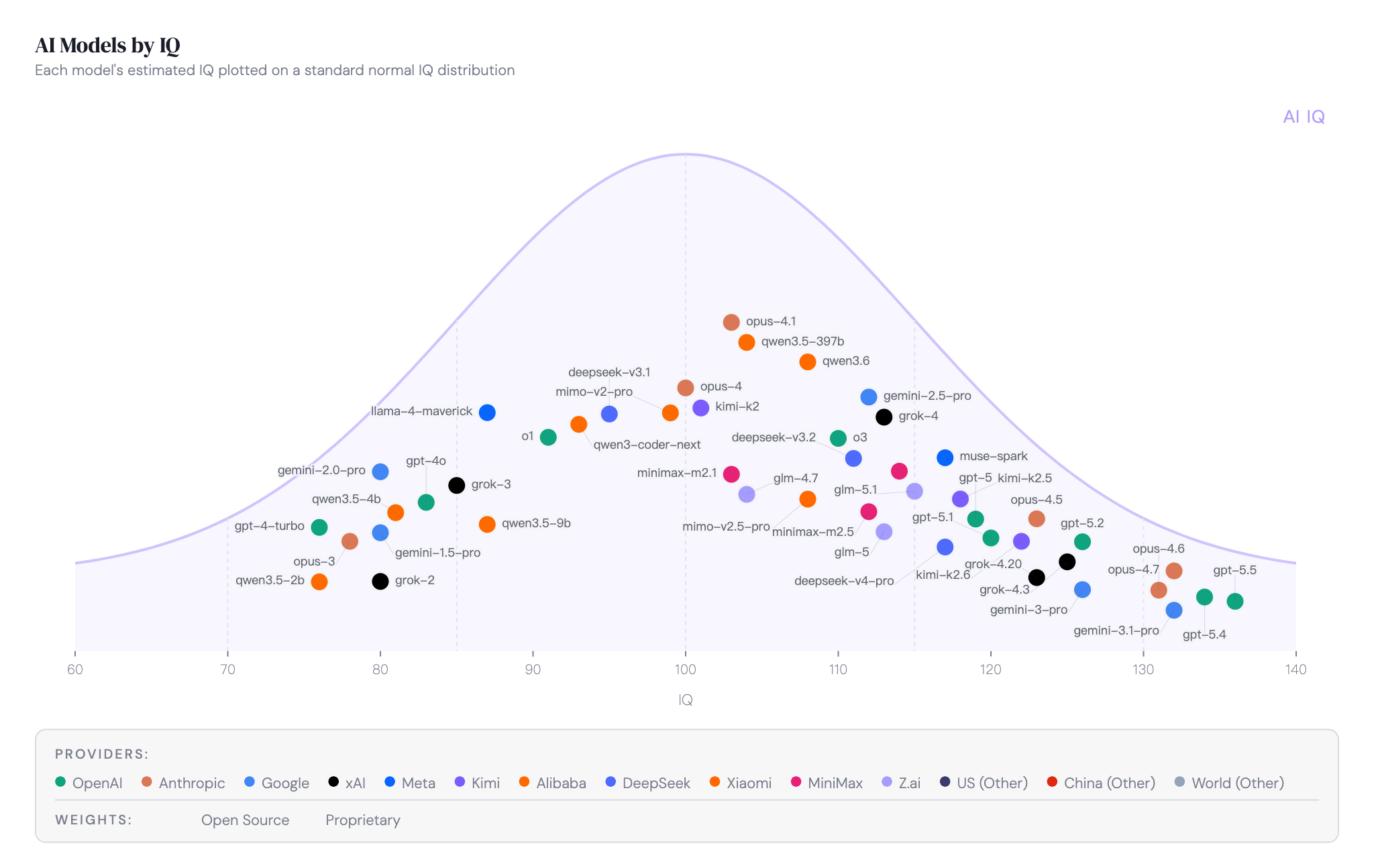
IQ 由四个维度组成:抽象推理、数学、编程、学术。要拿到综合分数,至少得覆盖其中两个维度。以下是头部选手:
| 排名 | 模型 | 厂商 | 亮点 |
|---|---|---|---|
| 1 | GPT-5.5 | OpenAI | ARC-AGI-2 85%,AIME 96.7% |
| 2 | Opus 4.7 | Anthropic | EQ 断层领先,编程全面 |
| 2 | Gemini 3.1 Pro | 数学最强,AIME 98.1% | |
| 4 | Kimi K2.6 | 月之暗面 | 开源,SWE-Bench 76.2% |
| 5 | Opus 4.6 | Anthropic | FrontierMath T1-3 118题 |
| 5 | Grok 4.3 | xAI | 196 TPS,速度碾压 |
| 7 | Qwen 3.6 | 阿里 | 各维度均衡 |
| 7 | DeepSeek V4 Pro | DeepSeek | 开源,BrowseComp 83.4% |
| 9 | GPT-5.4 | OpenAI | ProofBench 56% |
| 9 | GLM 5.1 | 智谱 | Tau2 98%,MCP Atlas 75.6 |
GPT-5.5 综合第一,但优势不算碾压。Opus 4.7 和 Gemini 3.1 Pro 跟得很紧,三者 IQ 差距在 5 分以内,不同测试的排名会有变化。
Kimi K2.6 排第四,作为开源模型这个成绩很能打。月之暗面在编程和数学两个维度上追得很紧。
Grok 4.3 的强项是速度。196 TPS 远超 Opus 4.7 的 46 TPS。对延迟敏感的场景,这个排名需要重新考虑。
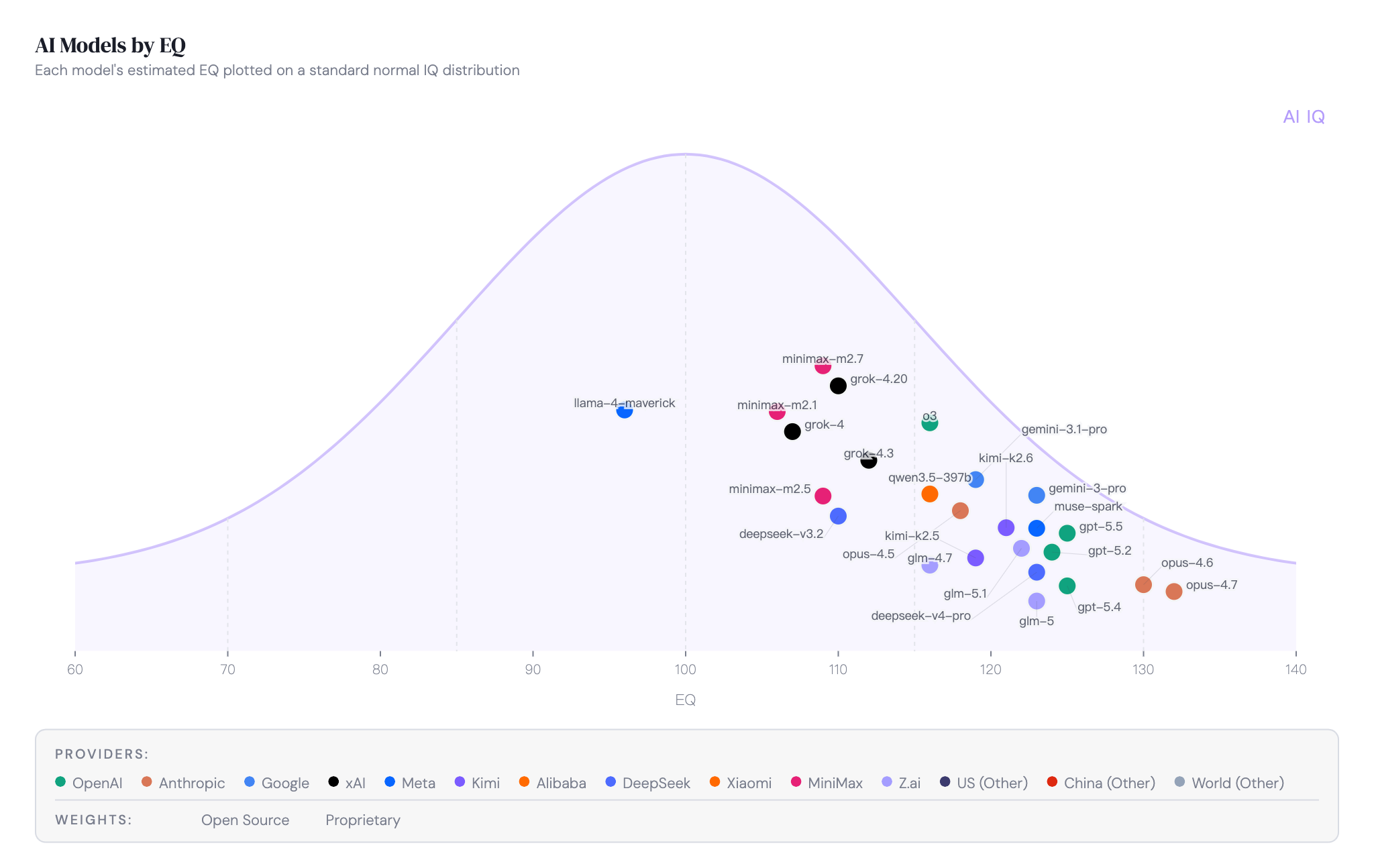
EQ 排名:Anthropic 的领地
EQ 由两部分组成:EQ-Bench 3 的 Elo 分数和 Chatbot Arena Elo。两者各占 50%。
| 排名 | 模型 | EQ-Bench Elo | Arena Elo |
|---|---|---|---|
| 1 | Opus 4.7 | 2035 | 1503 |
| 2 | Opus 4.6 | 1927 | 1504 |
| 3 | Sonnet 4.6 | 1891 | 1457 |
| 4 | GPT-5.4 | 1637 | 1479 |
| 5 | GLM 5 | 1650 | 1455 |
| 6 | DeepSeek V4 Pro | 1648 | 1462 |
| 7 | GPT-5.5 | 1627 | 1488 |
Anthropic 三款模型包揽前三。扣了 200 点惩罚之后 Opus 4.7 仍然甩了第二名一百多点。GPT-5.5 的 EQ 排名没有 IQ 那么高——聊天能力和推理能力确实不是同一回事。
Grok 4.20 的 EQ-Bench Elo 只有 852,排在倒数。xAI 的模型在情感理解上确实拖后腿。
分数是怎么来的
四个维度,每个维度对应几个基准测试:
- 抽象推理:ARC-AGI-1、ARC-AGI-2、CritPt
- 数学推理:AIME、FrontierMath Tier 4、SciCode
- 编程推理:Terminal-Bench 2.0、SWE-Bench Verified
- 学术推理:GPQA Diamond、Humanity's Last Exam 等
每个基准的原始分数通过一条校准曲线映射到对应的 IQ 值,四个维度取平均就是综合 IQ。公式很简单:
IQ = (抽象IQ + 数学IQ + 编程IQ + 学术IQ) / 4
缺失的维度用保守值填充后纳入平均。这意味着覆盖度低的模型不会占便宜,综合分数反而会被拉低。
成本:花多少钱买多少脑子
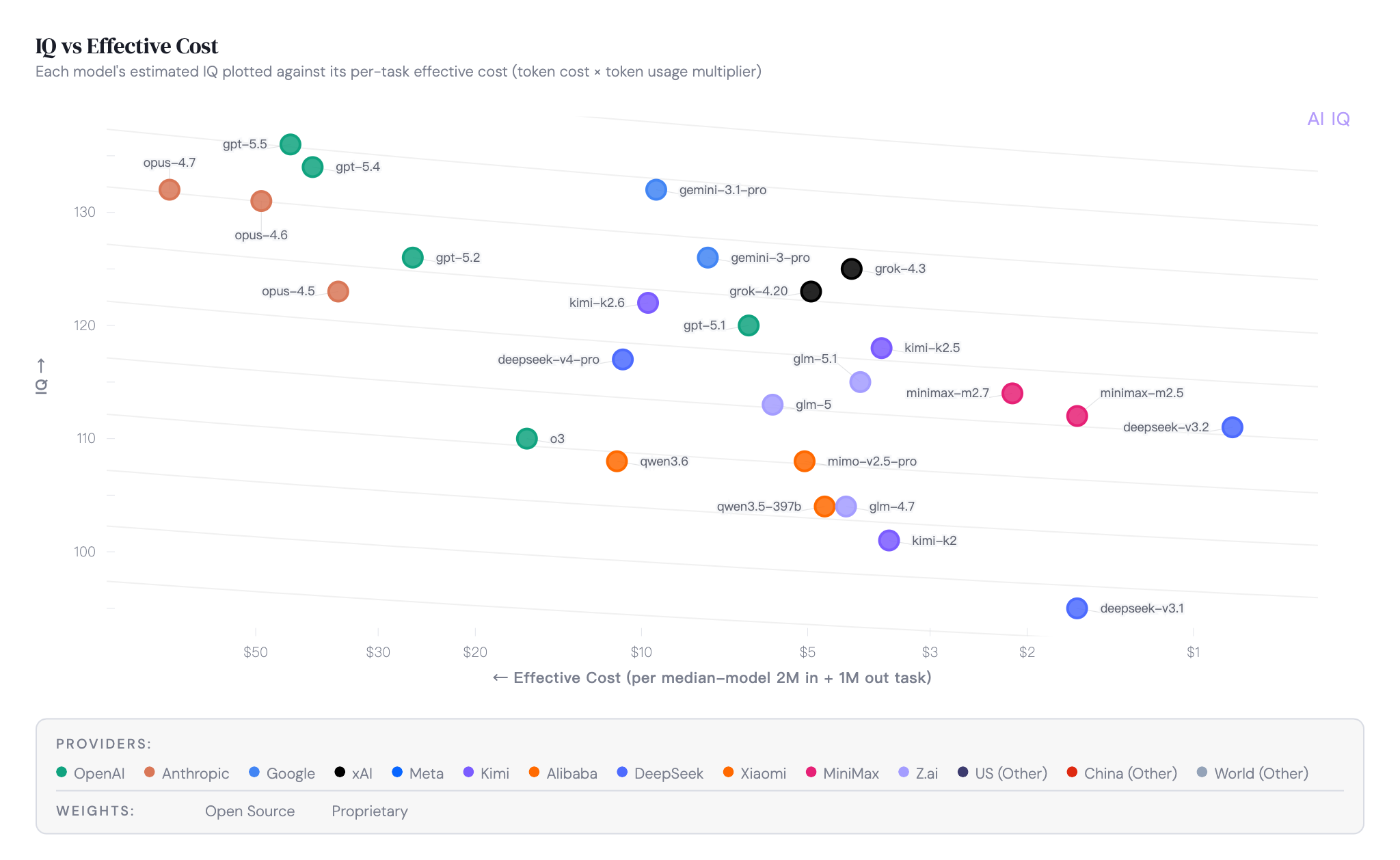
单纯比 IQ 高低意义不大。GPT-5.5 当然比 GPT-5-nano 聪明,但如果你只需要做文本分类,多付几十倍的钱就是浪费。
AI IQ 的"有效成本"概念比较实用:token 价格乘以 token 使用倍数。有些模型看起来便宜,但完成同样任务需要更多 token,实际算下来反而更贵。
| 模型 | 有效成本 | 一句话 |
|---|---|---|
| GPT-5.5 | $3357 | 最贵,能力也确实第一 |
| Opus 4.7 | $5335 | 性价比垫底,能力全面 |
| Qwen 3.5-397B | $418 | 开源里性价比最高的之一 |
| Kimi K2.6 | $948 | 中档价位的全能选手 |
| DeepSeek V3.2 | $76 | 百元以内最强 |
Opus 4.7 虽然能力全面,但 $5335 的有效成本让大多数场景望而却步。预算有限的话,DeepSeek V3.2 是 $100 以内的最佳选择——IQ 不算顶级,但绝对够用。
网站上那个 IQ vs 有效成本的散点图是最有用的视图。右上角的模型是严格意义上的更优选择,同等成本下更聪明,或者同等能力下更省钱。不用看参数,不用读论文。
几个值得提的设计
这个网站有几个选择让我觉得靠谱。
保守填充。缺失数据不直接忽略,而是用保守值填补后纳入平均。这个设计防止了"只挑简单测试跑"的策略。
前序对比。"Frontier IQ Over Time" 按发布日期排列各家旗舰模型,能直接看出新一代是不是真的比上一代有进步。发布会上说的"大幅提升",在这条线上有时只是一小步。
等值曲线。IQ 和成本的权衡可以用滑块调整权重比例。1:1 意味着 1 点 IQ 提升等价于成本减半,调到 1:5 就是成本更重要。不同场景的偏好不同,比单纯排名有用。
这些数据靠谱吗
IQ 这个概念本来就是从人类智力测试借过来的,用在 AI 上是否恰当,学术界也没有共识。不同基准之间的权重完全均等,但实际上有些测试更容易被数据污染。
EQ 的测量更模糊。情感理解能力和对话中的"讨人喜欢"到底是一回事吗?EQ-Bench 3 的裁判是 Claude 自己,虽然有修正,但"自己给自己打分"的结构本身就不太理想。
不过对于日常选模型来说,够用就行。你不需要一把完美的尺子,只需要一把比"厂商通稿"更靠谱的尺子。