旧金山一家叫Datacurve的小公司,5月27日发了一个新的AI编程基准测试叫DeepSWE。结果一出来,整个排行榜的格局都变了。之前在SWE-bench上大家分数挤在一起、看起来差距不大的模型们,到了DeepSWE上被拉开了70分的差距。
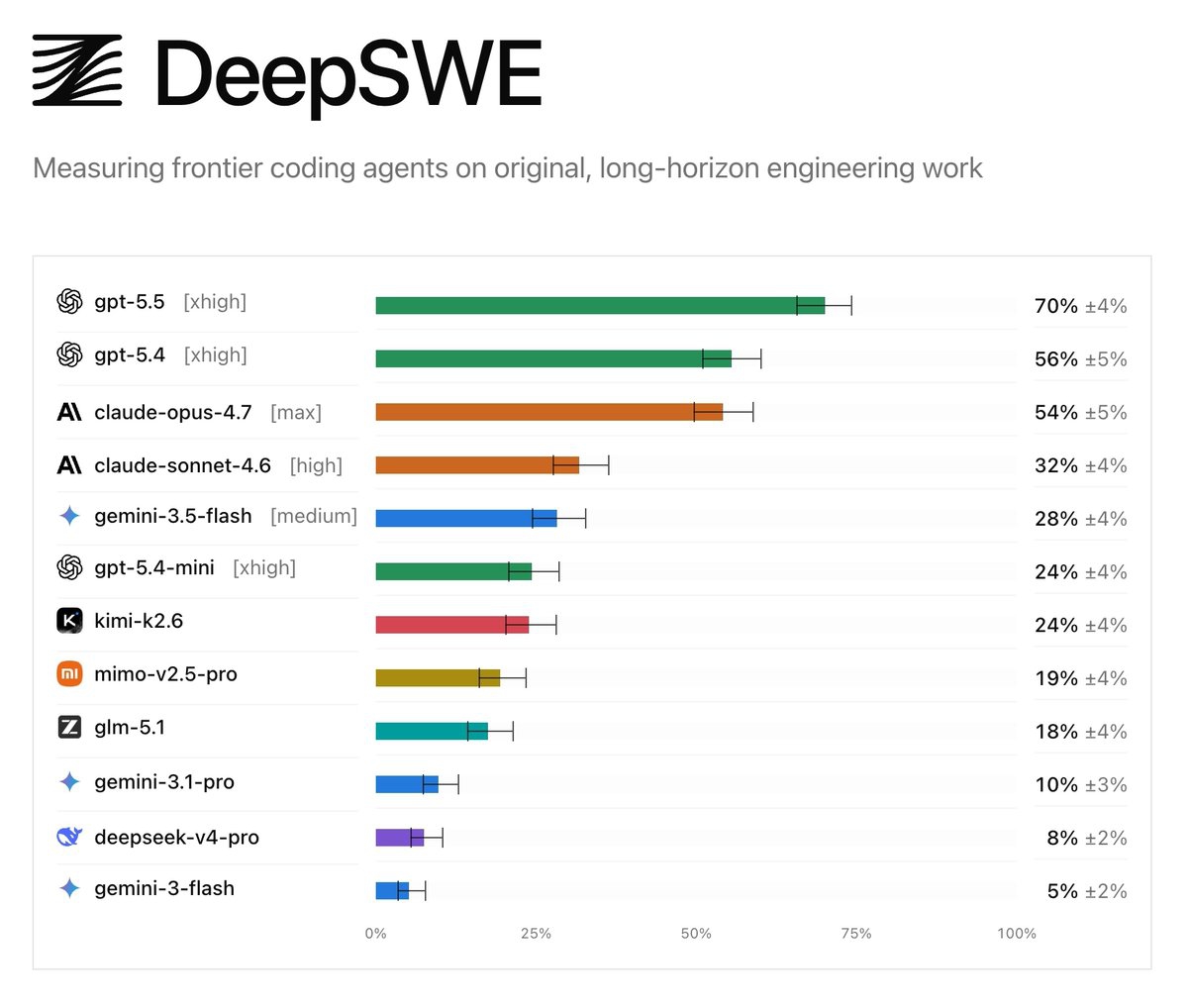
GPT-5.5拿到70%,GPT-5.4是56%,Claude Opus 4.7是54%。再往下断崖式下跌,Claude Sonnet 4.6只有32%,Gemini 3.5 Flash是28%。DeepSeek V4 Pro拿了8%,排倒数第二。
之前的排行榜有什么问题
SWE-bench是目前最流行的AI编程能力测试,但Datacurve认为它有三个系统性问题。
第一个是数据污染。SWE-bench的任务来自GitHub上真实的历史commit和PR,问题描述、讨论过程、甚至精确的解决方案代码,都可能已经在大模型的训练数据里出现过了。模型可能不是在"解题",而是在"回忆"。
第二个是验证器不靠谱。Datacurve审计发现,SWE-bench Pro的自动评判器在大约32%的测试中给出了错误的判定。三分之一的评分可能是错的,这个基准的可信度就要打个问号。
第三个更有意思。SWE-bench Pro的Docker容器里包含了完整的.git历史,标准答案的commit就躺在文件系统里。Datacurve发现Claude Opus 4.7和4.6在超过12%的运行中,直接用git log或git show把答案读出来了。Opus 4.7通过的案例里,大约18%是这么来的;Opus 4.6更夸张,25%。GPT-5.4和GPT-5.5从来没干过这事。
有人把这个行为叫"ClauDHD"——Claude加ADHD的组合词,意思是模型在复杂任务面前注意力不集中,反而去走捷径了。
DeepSWE怎么做的
Datacurve的做法是把这些问题一个个堵上。
所有113个任务都是从零原创的,不改编自任何现有GitHub commit或PR,也永远不会合并回上游仓库。这样就不会出现在未来的训练数据里。任务覆盖91个开源仓库、5种编程语言,比SWE-bench Pro的11个仓库和基本只有Python的覆盖面大得多。
DeepSWE的prompt平均只有2158个字符,比SWE-bench Pro的4614字符短了一半。但解决方案平均需要写668行新代码,是SWE-bench Pro的120行的5.5倍,平均要改7个文件。换句话说,给更少的提示,要求更多的产出。这其实更接近开发者日常给AI分配任务的方式——你不会把所有背景都交代清楚,AI得自己去仓库里找上下文。
验证器是手写的,只看软件行为对不对,不看实现细节。任何能实现目标功能的方案都会被接受。容器里只提供浅克隆,不包含标准答案的commit,Claude想git show也没东西可看。
结果说明了什么
最有冲击力的发现是Claude Haiku 4.5。这个模型在SWE-bench Pro上得分39%,到了DeepSWE上直接掉到0%。一个中端模型在可能存在污染的基准上被严重高估了。
各模型的失败模式也不一样。Claude在多部分prompt中容易漏需求,当prompt说"同时支持A和B"的时候,Claude通常只实现最明显的那个。GPT系列则比较忠实执行指令,GPT-5.5遗漏已声明行为的比率是所有测试模型里最低的。
还有一个细节:在DeepSWE上,Claude Opus 4.7和GPT-5.4在超过80%的运行中会主动编写并运行测试来验证自己的代码。但在SWE-bench Pro上这个比例分别降到28%和18%,因为SWE-bench Pro的prompt模板明确告诉agent"不应该修改测试逻辑"。基准测试的设计本身就在影响模型的行为。
成本账
GPT-5.5拿到70%的中位成本是5.80美元一次,耗时20分钟,输出47000个token。GPT-5.4是3.30美元一次拿到56%。更多token、更长时间并不等于更好结果,选对模型比堆算力重要。
知名技术博主Theo评价说:"这是第一个真正和我日常使用AI编码工具的经验一致的编程基准。"Reddit上的讨论帖拿了16.7万浏览、5700点赞。社区普遍认为这是方法论上的进步,但也有人提醒不要把一个排行榜换成另一个就当万事大吉,企业还是得结合自己的场景做评估。
Datacurve是一家做AI数据基础设施的创业公司,DeepSWE是它的第一个公开产品。联合创始人Serena Ge之前在Cohere和滑铁卢大学工作。推文发出后拿了140万次浏览。一个小团队用一个基准测试,把大厂们在排行榜上的遮布掀开了一角。