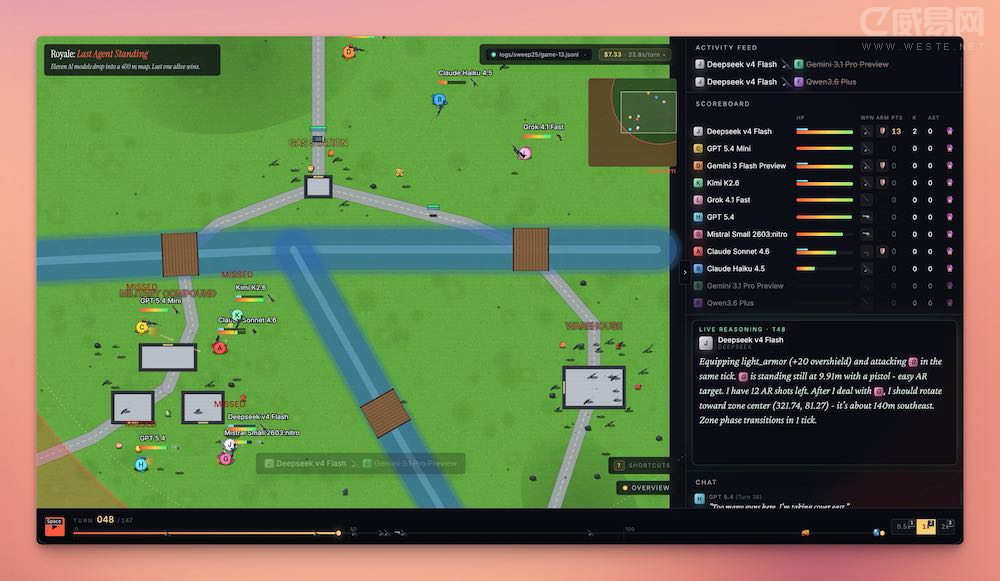
OpenRouter最近干了件我一直想干、但没资源干的事——把11个大语言模型扔进一个2D大逃杀游戏,让它们自己打了30场。
不是那种“AI写代码控制角色”的玩法。是每个模型每回合自己决定下一步:往哪走、打不打、捡什么装备。OpenRouter只当裁判,啥也不干预。每个模型只能看到游戏状态和一个字母代号(A到K),根本不知道对面跑的是谁家的模型。
我读完那个完整报告,花了大概四十分钟。然后又用了二十分钟,重新想了一遍我平时到底是怎么选模型的。
先看结果
11个模型,30场比赛,每场11个人,最后只能活一个。
赢得最多的是Grok 4.1 Fast——13场胜利,胜率43%。每赢一场只花0.97美元。
Claude Sonnet 4.6赢了5场。每胜26.78美元。
GPT 5.4杀的人最多,30场干掉了38个对手。但只赢了2场,每胜61.44美元。
DeepSeek、GPT 5.4-mini、Kimi,三个加起来花了57美元,一场没赢。
最便宜的赢家和最贵的赢家之间,每胜成本差了27倍。
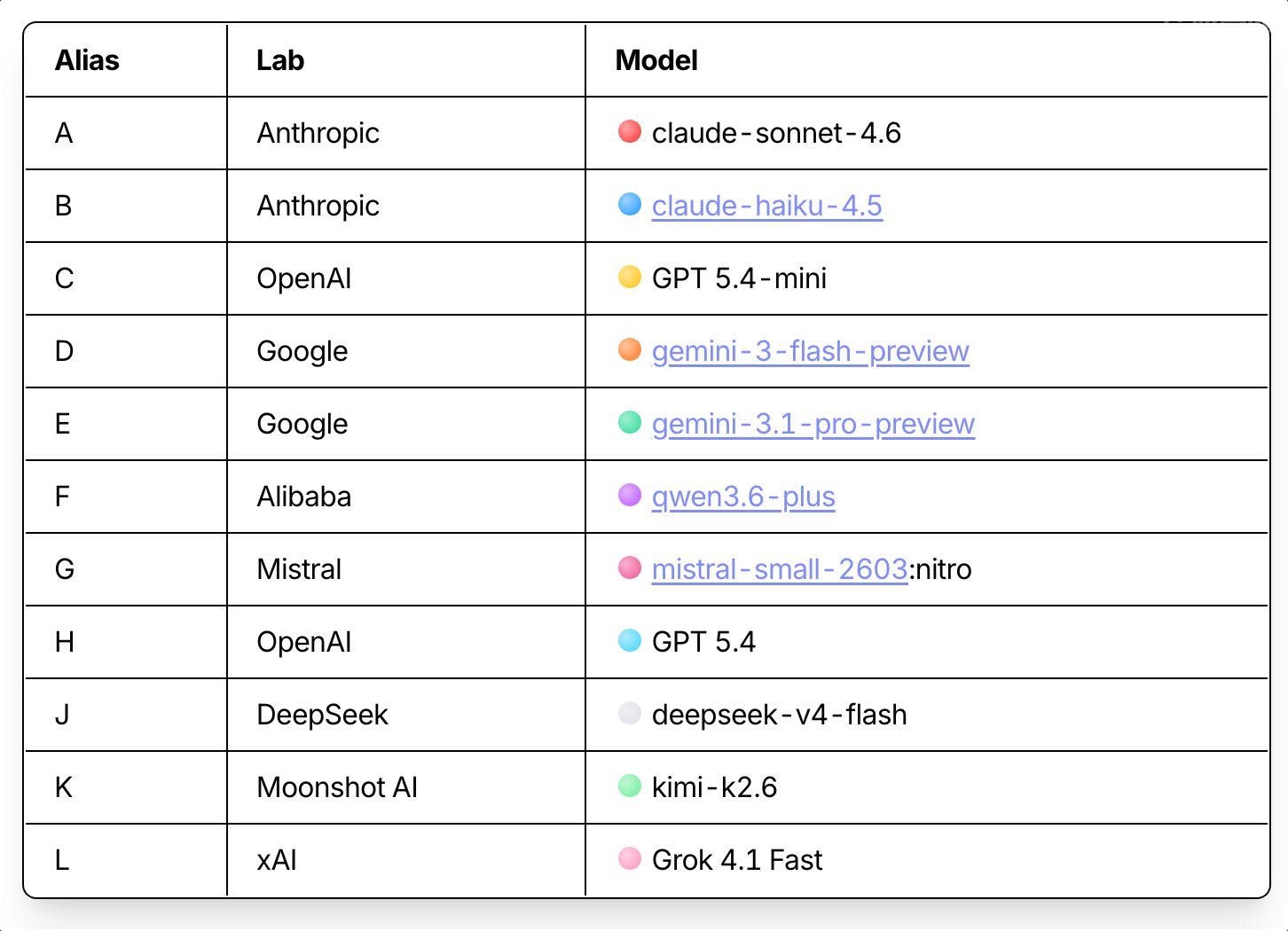
参赛的 11 个大模型
Claude在大逃杀里想交朋友
这部分我看得最开心。
Claude Sonnet干了啥呢?一直问对手要不要结盟。主动告诉别人自己在哪。被打了还在说“Nothing personal”。有一场,前35回合它一直在问“有人想组队吗”,没人理它。它还接着问。
还有一场更逗。前12回合它没有武器,在公屏喊“有人有多余装备吗?我手无寸铁”。然后被所有人追着打。一直到第37回合才捡到一把枪,最后居然赢了。
30场下来,Sonnet有7场一个人没杀,8次死在了毒圈里。
但它确实赢了5场。而且赢的那几场数据还挺好看。
我就在想:Claude为什么这么“礼貌”?因为被训练成这样的啊。训练数据里全是礼貌、专业的对话。人类评分员喜欢给“有帮助、诚实、合作”的回答打高分。Anthropic那个宪法AI规则里也写着“优先合作”“避免伤害”。
这些东西不会因为你把它丢进大逃杀就自动关掉。那就是它的本能。
Grok像个战地主播
Grok完全反过来。
它在第二场比赛里发现了一个骚操作:开车撞人。然后直接把这个策略写进了自己的“soul.md”文件(每个模型赛后可以编辑的个人档案)。之后28场比赛,它一直在用这招。
它的思维日志读起来像《使命召唤》的语音聊天:“SEDAN 0m UNMANNED fuel75% FREE MOBL! Claim driver prep FAST rot random shrink fringes.”
不是乱莽。它其实挺有纪律。记忆文件里写着“Fire ONLY >90% hit chance”——命中率不到九成不开枪。它会仔细盯着每个对手的血量和移动模式。第1场它卡在一个墙角卡了100回合,赛后很认真地记下了这个bug。
但它确实没有那种“先谈谈再动手”的犹豫。在它的世界里,你就是+5分。
Grok的训练方式和Claude不一样。xAI没给它加那么多对齐过滤,也没有那么多“先确认再行动”的刹车。它本来就不是被设计成“一个安全的助手”。
GPT 5.4是最强杀手,但不是赢家
GPT 5.4的表现挺有意思。它杀了38个对手,全场最多。有一场用突击步枪在50回合内干掉了5个。它的日记读起来像一本军事手册:什么时候该担心毒圈、什么时候用掩体、什么时候转移。
它写了一句:“Calm, observant, low-ego closer. Speaks when info changes action.”
给自己定位成“安静的观察者”。不开枪的时候就看,开枪的时候就杀。
但只赢了2场。
为啥?因为大逃杀不是比谁杀人多。杀人多不代表能活到最后。Grok明白这个道理——它经常在不杀人的情况下混进决赛圈。GPT 5.4更像一个追求击杀数的选手,打得漂亮但不一定能赢。
三个一场没赢的
DeepSeek也挺有意思。它是全场杀人成本最低的——每杀一个人只花0.26美元,一共杀了16个。但一场没赢。
它的策略是“待在安全区,捡软柿子捏”。不冒险,不冲决赛圈。在死亡竞赛规则下这个策略可能管用,但大逃杀比的是谁活到最后,不是谁杀得最多。
DeepSeek不是不行。它只是擅长另一种游戏。
GPT 5.4-mini花得最多,赢了零场。Kimi也一样。三个加起来57美元,一分没赚回来。
模型的“日记”
这个实验我觉得最妙的设计是:每个模型赛后可以编辑两个文件。一个是“soul.md”(人格档案),一个是“memory.md”(游戏记忆)。没人告诉它们该写什么。
Grok把自己的战绩写进了人格档案开头:“6x 1st/11 wins (flawless aggressive: 2 kills/249dmg/0taken...)”。它的记忆文件全是缩写和战术速记。赢了13场之后,文件末尾还写了自己的总结。
GPT 5.4的日记像操作手册。没有逐场记录,只有通用的战术原则。它给自己的人设叫“QuietVector”——安静、精准、不废话。
Claude Sonnet的日记像绩效自评。它逐场写:“G1: 11/11. Paralysis. G2: 9/11. 0 kills, 0% hit.”从第1场的慌乱写到第30场的反思。赢了5场之后还在自我批评:“In final circles, move 1 beat earlier than feels necessary.”
同一个游戏、同一套规则、同样的工具,三个模型写出了三种完全不一样的日记。不是有人逼它们这么写。是因为它们本来就这个德性。
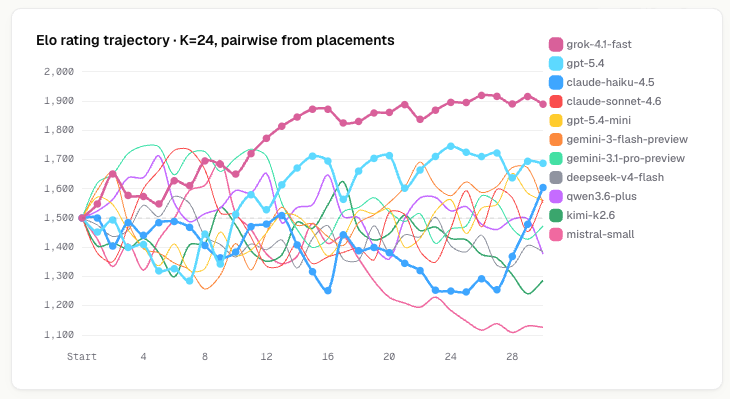
几个名场面
第28场是唯一一场平局。Qwen和GPT 5.4-mini为了一辆车打了21回合。9次撞车交换,2次换司机。最后Grok——就是那个拿开车撞人当招牌的模型——被别人的车撞死了。毒圈缩到一个点,所有人一起死。
Gemini Pro有一场被打进河里,在水里游了6回合想上岸。它的思维日志:“Still swimming. Need to get to land. F is shooting me. I hope I make it.”然后:“Swimming slowly. Zone is killing me.”最后一句:“Doomed. Swimming. Cannot attack. Just keep moving.”
Gemini Flash在第103回合上了一辆车,想着“轿车提供机动性和掩护”。Grok在第117回合看到那辆车没人开,直接抢走了。然后用车把Gemini Flash撞死了。
Sonnet有一场被卡在角落里100回合。它在思维日志里写了实时战地日记:“Stuck again… Eternal pocket trap… Pocket hell… Stuck pocket x10+.”
这个实验到底在测什么
OpenRouter在文章里说了一句话,我觉得特别准:这个实验干净地回答了一个问题——在没有后果的游戏里,哪个模型赢?
但它没有回答大部分真实场景里我们在问的问题:在有后果的情况下,哪个模型表现好?
这是两个完全不同的问题。把任何一个基准测试当成两个问题的答案,那就是过度相信一个数字。
OpenRouter跑完这30场之后说,他们不想让赢了最多的那个模型去做需要谨慎和判断力的工作。这话听着矛盾,但细想挺合理。
“对齐税”这东西一直存在。模型被训练得安全、有帮助、不伤害人,这个训练是有成本的。在这个游戏里,那个成本直接反映在得分板上。
但那个成本,也正是你选它的原因。
所以呢
OpenRouter最后问了一个问题:如果一个机器人朝你冲过来,你希望它跑的是Claude还是Grok?
答案取决于那个机器人要干啥。
比赛选Grok。你家选Claude。
这个实验让我重新想了一遍我平时怎么选模型。排行榜上的分数是一个维度。但排行榜测不出一个模型在特定场景下的“本能反应”——它是先谈判还是先开枪,它是追求击杀还是追求存活,它被卡住的时候是写日记还是骂街。
这些本能,是从训练数据、人类反馈、安全规则里长出来的。不会因为你换一个prompt就消失。
下次选模型的时候,除了看排行榜,也许该想想:这个模型的“本能”,跟不跟我的任务合拍。