6��30�գ���Ϊ��ʽ������Դ�̹Ŵ�ģ��openPangu 2.0 Flash�汾����־����ҿƼ���ͷ��������ģ������Ŀ�Դս�������ؼ�һ�����˴ο�Դ���ݺ���ģ��Ȩ�ء������������뼰ѵ�����ӣ���ȫ�����߿�Դƽ̨����ȫ��������ʹ�á�
�ӷ�����ţ���ж����Թ�˧
��һʱ��ڵ�ĵ�����Դ������ǰ��Ϊ�����ߴ�ᣨHDC 2026���ϵ�һ�θߵ����档��Ϊ�����¡���ƷͶ������ίԱ�����Ρ��ն�BG���³���ж����Ե�̨����ʽ����openPangu 2.0������������6��30����½����Դ7��������������ģ�ͽṹ��ģ��Ȩ�ء��������桢�������롢Ԥѵ�����롢��ѵ�����뼰ѵ�����ӡ�
��ж����ݽ���̹����һ����Ϊ���������ҷ�˼����Ϊ��ȫ���綼��֪����ģ��Ϊ����ʱ���㷢���˹�������ģ�ͣ�����ҵ��"��������"��������������ԭ��"û���ã���Ӧ��"����¶��ȥ������ǰϦ�����������������̹Ŵ�ģ��ҵ���漴��һ��ǿӲ��̬���»���——"����ж��ֵ��û�еڶ���ֻ�е�һ��"
˫�汾��֣�Flash���У�Pro���¸���
openPangu 2.0����Pro��Flash˫�첢�еIJ�Ʒ���ԣ����߾�֧��512K���������Ĵ��ڣ��Ը��Ǵ������������콢��Ӧ�õIJ�ͬ��������
Flash�汾��Ϊ����Դ�汾���ܲ�����Ϊ92B�������������Ϊ6B���Լ��ߵ�ϡ��ȣ����28:1��ʵ���˳�ɫ������Ч�ʣ���Ҫ����������������Pro�汾�����콢�������ܲ������ﵽ505B�����������18B�����ǿ����Agent����ִ����������ģ��Ȩ��������������뽫��7�����߿�Դƽ̨�����Դ������ڽ����°���½�����������š�
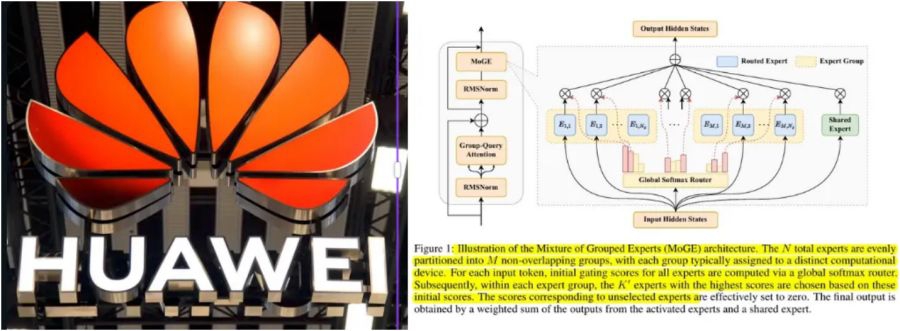
������ɫ���N��ԭ���ܹ���ϡ��MoE����
openPangu 2.0�ļ�������֮һ��������������仪Ϊ�N�ڣ�Ascend��NPU�ļܹ���ơ��ٷ�������ʾ���ڕN��Ӳ���ӳ��£���ģ�͵��������ʿɴ�ҵ��������Դģ�͵�2������������ӲЭͬ�Ż�������������
��ģ�ͼܹ��ϣ�openPangu 2.0������һ����Ϊ��Ϸ���ר�ң�MoGE��Mixture of Grouped Experts���Ĵ�����ơ��üܹ���ȫ��·����֮�ϣ���ר�����簴�豸�������飬ÿ��Token��Լ��Ϊ�������������ڼ���̶�������ר�ң����Ǵ�ȫ��ר�ҳ������ɾ�ѡ����һ���ƴӹ����Ͻ��豸��ĸ��ز�����÷�����Ϊ�㣬�Ӹ����������˴�ͳMoE·����"ij�ſ�æ������һ�ſ�����"�ľ���ʹ�㣬ʹ���ģ�ֲ�ʽ������Ч�����ȶ��Եõ����ϡ�
�����Ա��֣��������ԣ��̰����
�ӵ����������Եij�������������openPangu 2.0��˼ά����Thinking��ģʽ���ֿ�Ȧ�ɵ㣺��AIME 2026��λ��ȫ��Լ��8������LiveCodeBench V6��������9��չ�ֳ���ǿ����ѧ�����������������Ա����Ļ��������ڲ�ʿ����ѧ�ʴ�GPQA-Diamond��Լ��26�����Լ���������ʵս���⣨SWE-bench Verified��Լ��50���������ڽ�һ�������Ŀռ䡣
��Դս�Եĸ����⺭
openPangu 2.0�Ŀ�Դ�����й�ͷ���Ƽ���ҵ�ڴ�ģ���������������̬����һ��Ӱ����DeepSeek��ͨ��ǧ�ʵȹ�����Դģ���ѻ��۴���ȫ���������ڱ��ı����£���Ϊ�˷������ó���ģ��Ȩ�أ���ͬ���ͷ�ѵ���������������룬���ֳ���ȫ��·��Դ�ĸ��߳��⡣
��Ϊֵ�ù�ע���ǣ�openPangu 2.0ȫ�̻��ڻ�Ϊ�N��NPUѵ��������ζ������Դ��̬——��Ӳ����оƬ����ջ��CANN����ģ�ͱ���——�������������ɿصļ�����ϵ֮�ϣ��ڵ�ǰ����оƬ��Ӧ���߶Ȳ�ȷ���Ļ����£���һ����г�Խģ�����ܱ�����ս�����塣
Ŀǰ��ģ��Ȩ�����ڿ�Դƽ̨���ߣ�ͬʱ�ṩ���ڕN������ϵͳ��MindIE��vLLM-Ascend������ʾ�����룬��֧����Transformers��ܣ�torch 2.1.0�����ϣ������У�����Ȩ�ؽ��ڽ��ڷ�����